Documentation Index
Fetch the complete documentation index at: https://docs.together.ai/llms.txt
Use this file to discover all available pages before exploring further.
Job Timing
How long will it take for my job to start?
It depends. Factors that affect waiting time include the number of pending jobs from other customers, the number of jobs currently running, and available hardware. If there are no other pending jobs and there is available hardware, your job should start within a minute of submission. Typically jobs will start within an hour of submission. However, there is no guarantee on waiting time.How long will my job take to run?
It depends. Factors that impact your job run time are model size, training data size, and network conditions when downloading/uploading model/training files. You can estimate how long your job will take to complete training by multiplying the number of epochs by the time to complete the first epoch.Pricing and Billing
How can I estimate my fine-tuning job cost?
To estimate the cost of your fine-tuning job:- Calculate approximate training tokens:
context_length × batch_size × steps × epochs - Add validation tokens:
validation_dataset_size × evaluation_frequency - Multiply the total tokens by the per-token rate for your chosen model size, fine-tuning type, and implementation method
Fine-Tuning Pricing
Fine-tuning pricing is based on the total number of tokens processed during your job, including training and validation. Cost varies by model size, fine-tuning type (Supervised Fine-tuning or DPO), and implementation method (LoRA or Full Fine-tuning). The total cost is calculated as:total_tokens_processed × per_token_rate
Where total_tokens_processed = (n_epochs × n_tokens_per_training_dataset) + (n_evals × n_tokens_per_validation_dataset)
For current rates, refer to our fine-tuning pricing page.
The exact token count and final price are available after tokenization completes, shown in your jobs dashboard or via tg fine-tuning retrieve $JOB_ID.
Dedicated Endpoint Charges for Fine-Tuned Models
After fine-tuning, hosting charges apply for dedicated endpoints (per minute, even when not in use). These are separate from job costs and continue until you stop the endpoint. To avoid unexpected charges:- Monitor active endpoints in the models dashboard
- Stop unused endpoints
- Review hosting rates on the pricing page
Understanding Refunds When Canceling Fine-Tuning Jobs
When you cancel a running fine-tuning job, you’re charged only for completed steps (hardware resources used). Refunds apply only for uncompleted steps. To check progress: Useclient.fine_tuning.retrieve("your-job-id").total_steps (replace with your job ID).
For billing questions, contact support with your job ID.
Errors and Troubleshooting
Why am I getting an error when uploading a training file?
Common issues:- Incorrect API key (403 status).
- Insufficient balance (minimum $5 required). Add a credit card or adjust limits. If balance is sufficient, contact support.
Why was my job cancelled?
Reasons:- Insufficient balance.
- Incorrect WandB API key.
$ together list-events <job-fine-tune-id> or web interface.
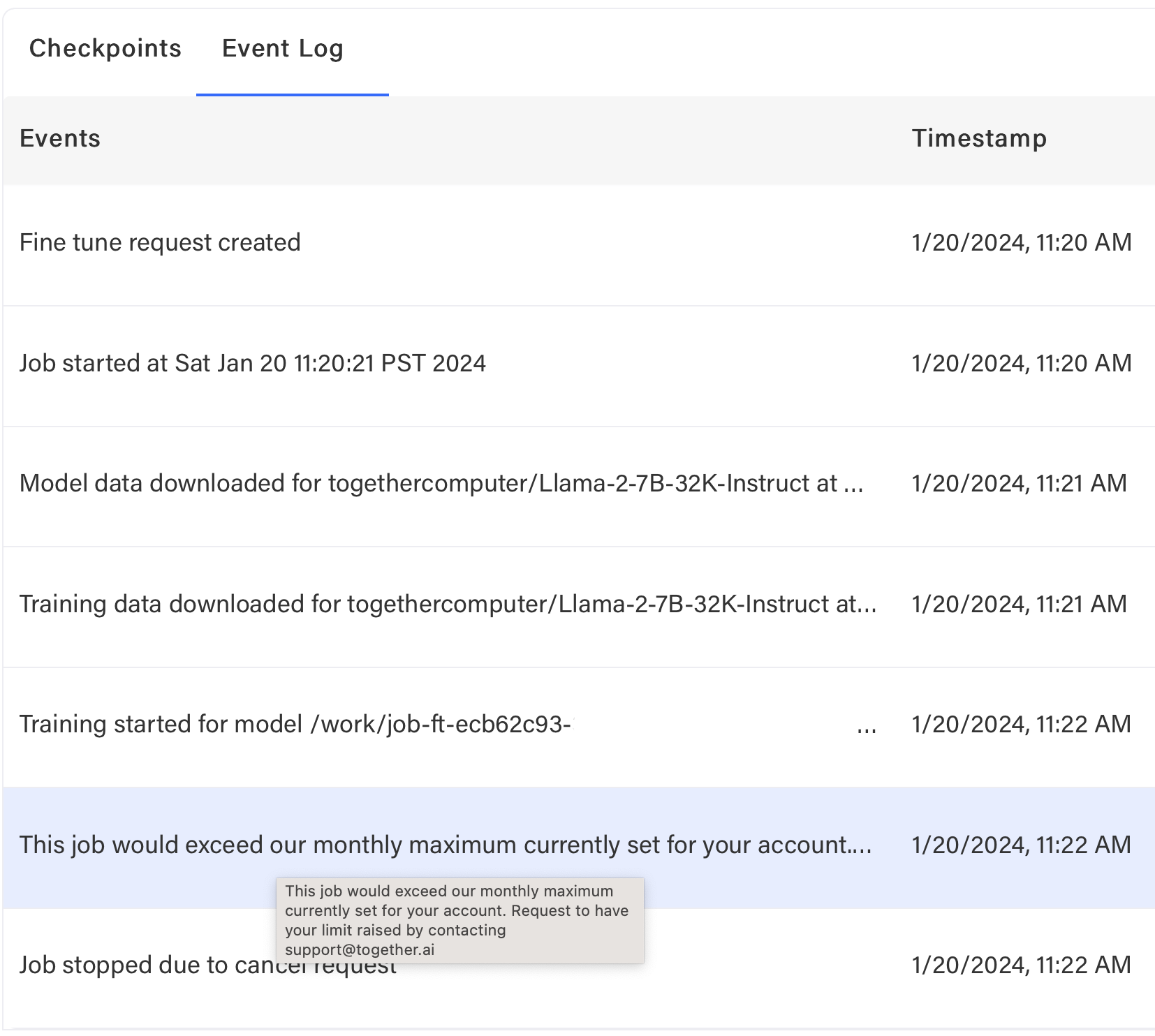
What should I do if my job is cancelled due to billing limits?
Add a credit card to increase your spending limit, make a payment, or adjust limits. Contact support if needed.Why was there an error while running my job?
If failing after download but before training, likely training data issue. Check event log: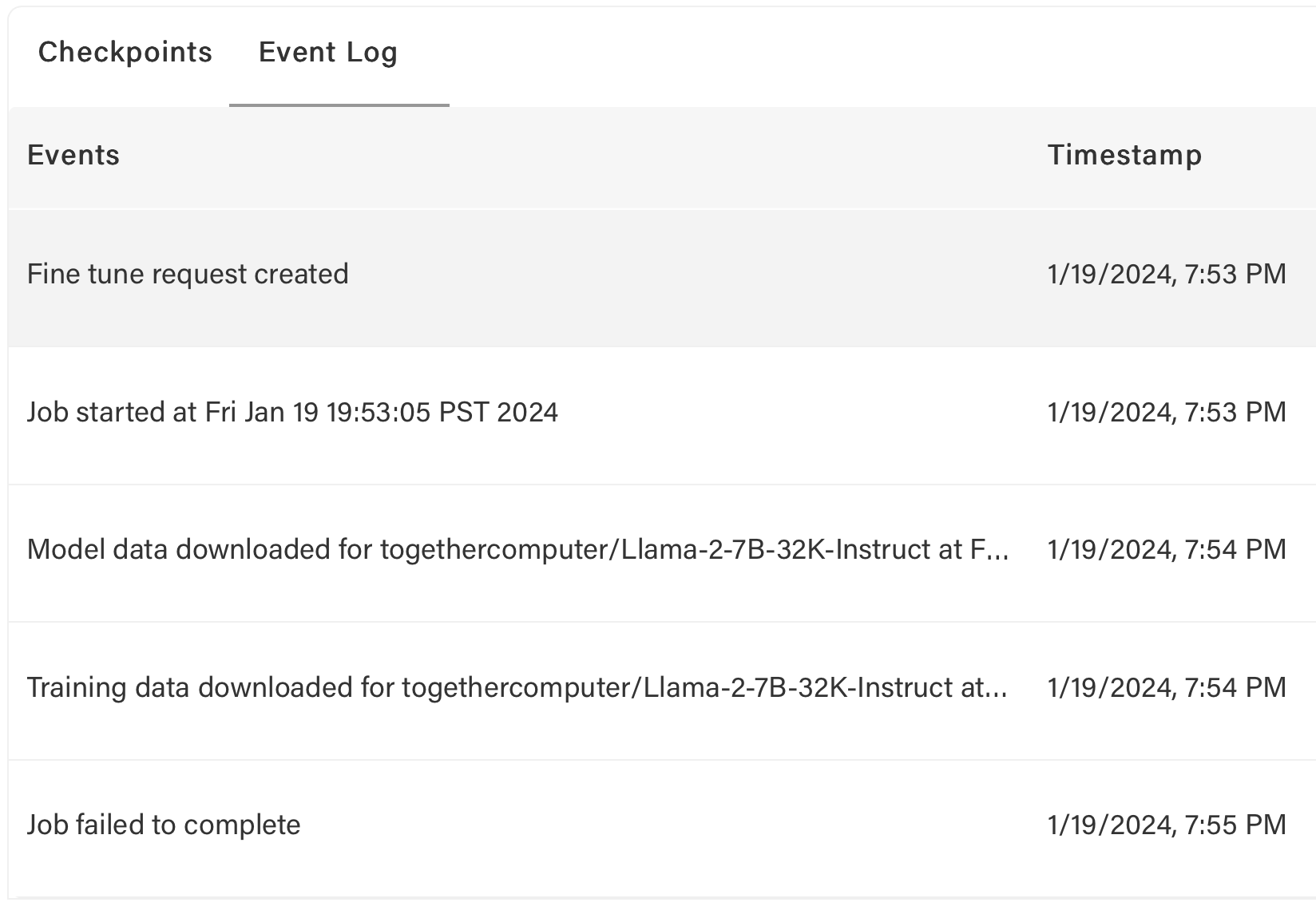
$ tg files check ~/Downloads/unified_joke_explanations.jsonl
If data passes checks but errors persist, contact support.
For other errors (e.g., hardware failures), jobs may restart automatically with refunds.
How do I know if my job was restarted?
Jobs restart automatically on internal errors. Check event log for restarts, new job ID, and refunds. Example: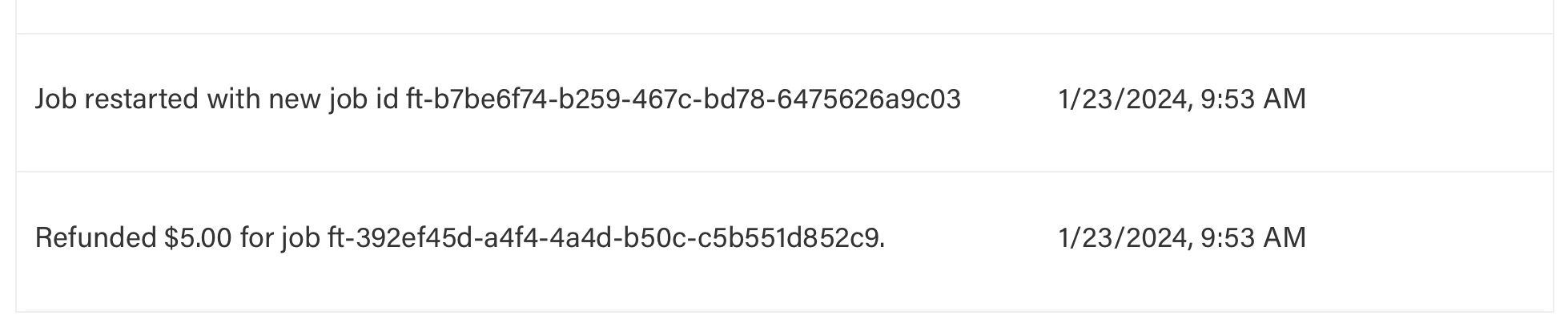
Common Error Codes During Fine-Tuning
| Code | Cause | Solution |
|---|---|---|
| 401 | Missing or Invalid API Key | Ensure you are using the correct API Key and supplying it correctly |
| 403 | Input token count + max_tokens parameter exceeds model context length | Set max_tokens to a lower number. For chat models, you may set max_tokens to null |
| 404 | Invalid Endpoint URL or model name | Check your request is made to the correct endpoint and the model is available |
| 429 | Rate limit exceeded | Throttle request rate (see rate limits) |
| 500 | Invalid Request | Ensure valid JSON, correct API key, and proper prompt format for the model type |
| 503 | Engine Overloaded | Try again after a brief wait. Contact support if persistent |
| 504 | Timeout | Try again after a brief wait. Contact support if persistent |
| 524 | Cloudflare Timeout | Try again after a brief wait. Contact support if persistent |
| 529 | Server Error | Try again after a wait. Contact support if persistent |
Model Management
Can I download the weights of my model?
Yes, to use your fine-tuned model outside our platform: Run:tg fine-tuning download <FT-ID>
This downloads ZSTD compressed weights. Extract with tar -xf filename.
Options:
--output,-o(filename, optional) — Specify output filename. Default:<MODEL-NAME>.tar.zst--step,-s(integer, optional) — Download specific checkpoint. Default: latest (-1)